










学了一段时间的爬虫,给自己找一个小项目来练练手,爬取百度百科文章,之后结合自然语言处理分析文本之间的相似度和提取所有文章的重要信息。
目标总览
1. 爬取数据(selenium + BeautifulSoup)
2. 清洗数据(pandas + re)
3. 可视化展示(matplotlab + seaborn + plotly)
4. 词云展示(juba + wordart)
5. 文章相似度分析(juba + graphlab)
1. 爬取百度学术文章
首先,我们打开百度学术首页:http://xueshu.baidu.com/
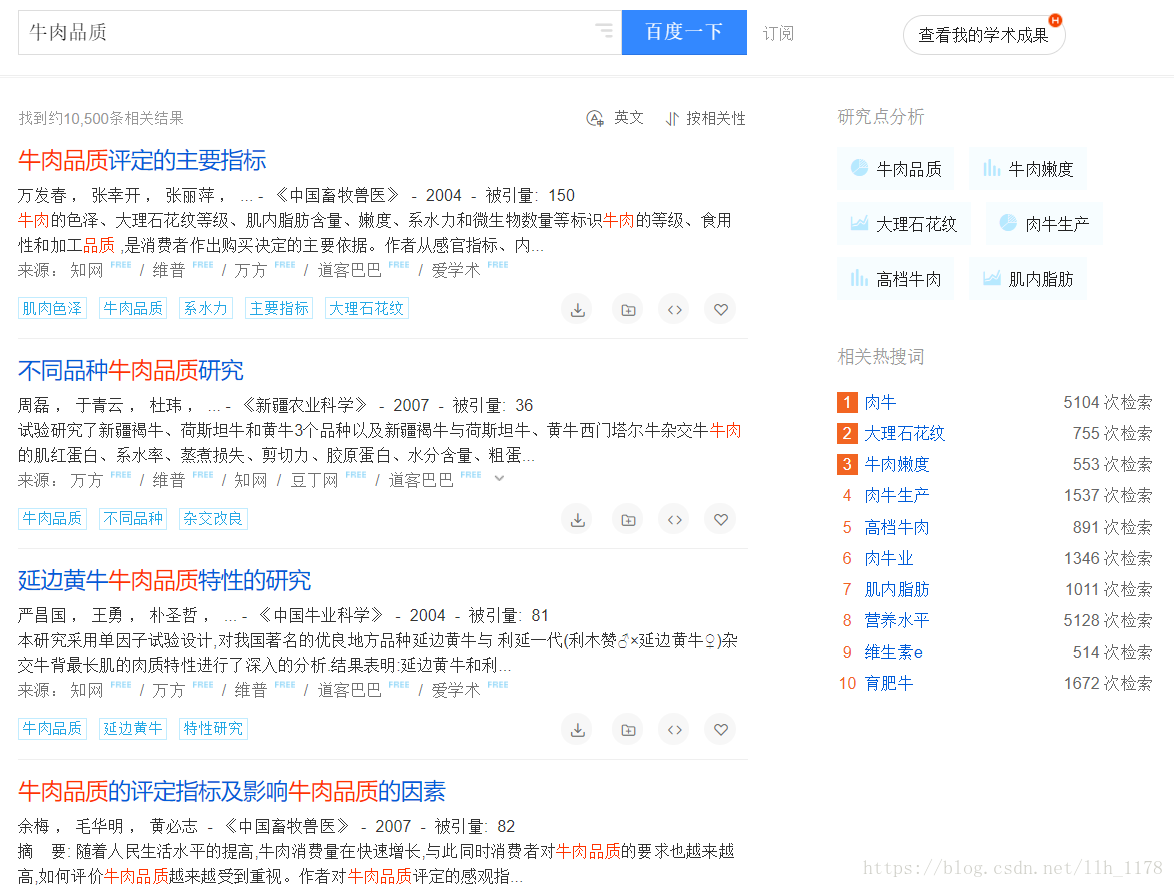
可以看到我们需要填入关键词,才能进行搜索我们需要的类型文章,在此我以“牛肉品质”为例,进行搜索。我们在搜索栏中单击鼠标右键,在单击检查,查看源码。
用相同的方法查看“百度一下”。
这样做的目的是为了使用selenium进行自动输入,并搜索。
这里写一个方法,传入一个参数——要输入的关键词。我是使用的谷歌浏览器的driver,也可以使用PhantomJS无界面的driver。



from bs4 import BeautifulSoup
from selenium import webdriver
import time
import pandas as pd
import requests
import re
from collections import defaultdict
def driver_open(key_word):
url = "http://xueshu.baidu.com/"
# driver = webdriver.PhantomJS("D:/phantomjs-2.1.1-windows/bin/phantomjs.exe")
driver = webdriver.Chrome("D:\\Program Files\\selenium_driver\\chromedriver.exe")
driver.get(url)
time.sleep(10)
driver.find_element_by_class_name('s_ipt').send_keys(key_word)
time.sleep(2)
driver.find_element_by_class_name('s_btn_wr').click()
time.sleep(2)
content = driver.page_source.encode('utf-8')
driver.close()
soup = BeautifulSoup(content, 'lxml')
return soup
然后,进入搜索界面,我们接着分析。我们需要抓取文章的题目,同时要进行翻页爬取多页。
怎么样实现发现呢?我们点开多个页面观察网页URL:
第一页:
http://xueshu.baidu.com/s?wd=%E7%89%9B%E8%82%89%E5%93%81%E8%B4%A8&pn=0&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D%7BfirstSimpleSearch%7D&sc_hit=1
第二页:
http://xueshu.baidu.com/s?wd=%E7%89%9B%E8%82%89%E5%93%81%E8%B4%A8&pn=10&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D%7BfirstSimpleSearch%7D&sc_hit=1
第三页:
http://xueshu.baidu.com/s?wd=%E7%89%9B%E8%82%89%E5%93%81%E8%B4%A8&pn=20&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&f=3&sc_f_para=sc_tasktype%3D%7BfirstSimpleSearch%7D&sc_hit=1
可以发现这三页URL中只有一个地方发生了改变,就是“pn”的值,从0开始,然后每次递增10,所以,我们通过这个就可以很好的实现翻页了。
def page_url_list(soup, page=0):
fir_page = "http://xueshu.baidu.com" + soup.find_all("a", class_="n")[0]["href"]
urls_list = []
for i in range(page):
next_page = fir_page.replace("pn=10", "pn={:d}".format(i * 10))
response = requests.get(next_page)
soup_new = BeautifulSoup(response.text, "lxml")
c_fonts = soup_new.find_all("h3", class_="t c_font")
for c_font in c_fonts:
url = "http://xueshu.baidu.com" + c_font.find("a").attrs["href"]
urls_list.append(url)
return urls_list
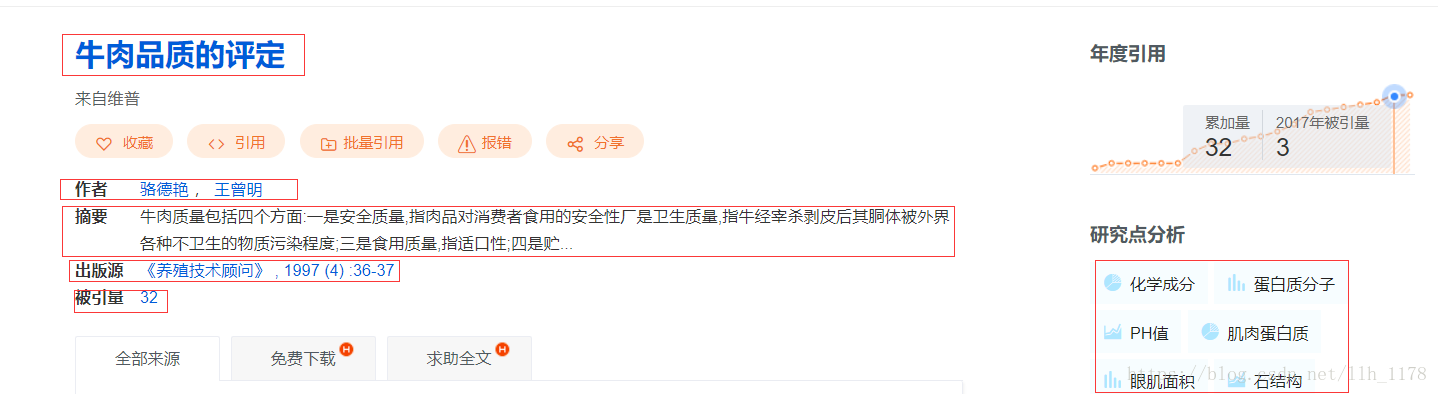
接下来就是对感兴趣的地方实施抓取了。我们进入详情页,我们需要抓取的东西有:题目、摘要、出版源、被引用量,有关键词。
还是按照老方法,将这些需要爬取的东西一个一个检查源码,用CSS select 方法处理。
def get_item_info(url):
print(url)
# brower = webdriver.PhantomJS(executable_path= r"C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe")
# brower.get(url)
# time.sleep(2)
# more_text = brower.find_element_by_css_selector('p.abstract_more.OP_LOG_BTN')
# try:
# more_text.click()
# except:
# print("Stopping load more")
# content_details = brower.page_source.encode('utf-8')
# brower.close()
# time.sleep(3)
content_details = requests.get(url)
soup = BeautifulSoup(content_details.text, "lxml")
# 提取文章题目
title = ''.join(list(soup.select('#dtl_l > div > h3 > a')[0].stripped_strings))
# 提取文章作者
authors = ''.join(str(author_) for author_ in list(soup.select('div.author_wr')[0].stripped_strings)[1:])
# 提取摘要
abstract = list(soup.select('div.abstract_wr p.abstract')[0].stripped_strings)[0].replace("\u3000", ' ')
# 提取出版社和时间
fir_publish_text = list(soup.select('p.publish_text'))
if len(fir_publish_text) == 0:
publish_text = "NA"
publish = "NA"
year = "NA"
else:
publish_text = list(soup.select('p.publish_text')[0].stripped_strings)
publish = publish_text[0]
publish = re.sub("[\r\n ]+", "", publish)
publish_text = ''.join(publish_text)
publish_text = re.sub("[\r\n ]+", "", publish_text)
# 提取时间
match_re = re.match(".*?(\d{4}).*", publish_text)
if match_re:
year = int(match_re.group(1))
else:
year = 0
# 提取引用量
ref_wr = list(soup.select('a.sc_cite_cont'))
if len(ref_wr) == 0:
ref_wr = 0
else:
ref_wr = list(soup.select('a.sc_cite_cont')[0].stripped_strings)[0]
# 提取关键词
key_words = ','.join(key_word for key_word in list(soup.select('div.dtl_search_word > div')[0].stripped_strings)[1:-1:2])
# data = {
# "title":title,
# "authors":authors,
# "abstract":abstract,
# "year":int(year),
# "publish":publish,
# "publish_text":publish_text,
# "ref_wr":int(ref_wr),
# "key_words":key_words
# }
return title, authors, abstract, publish_text, year, publish, ref_wr, key_words
这里有特别说明一下:在爬取摘要的时候,有一个JS动态加载,“更多”样式加载按钮。所以,我想要将摘要全部爬下来,可能就要使用selenium模仿点击操作(我在代码中加了注释的地方)。但是,我没有用这种方式因为多次访问网页,可能会有很多问题,一个是速度的问题,一个是很容易被服务器拒绝访问,所以在这里我只爬取了一部分摘要。
接着保存爬取的数据,这里我为了后面直接用pandas读取处理,且数据量不大,所以直接保存为csv格式。
def get_all_data(urls_list):
dit = defaultdict(list)
for url in urls_list:
title, authors, abstract, publish_text, year, publish, ref_wr, key_words = get_item_info(url)
dit["title"].append(title)
dit["authors"].append(authors)
dit["abstract"].append(abstract)
dit["publish_text"].append(publish_text)
dit["year"].append(year)
dit["publish"].append(publish)
dit["ref_wr"].append(ref_wr)
dit["key_words"].append(key_words)
return dit
def save_csv(dit):
data = pd.DataFrame(dit)
columns = ["title", "authors", "abstract", "publish_text", "year", "publish", "ref_wr", "key_words"]
data.to_csv("abstract_data.csv", index=False, columns=columns)
print("That's OK!")
到此,程序完成,然后开始爬取前20页的数据:
if __name__ == "__main__":
key_word = "牛肉品质"
soup = driver_open(key_word)
urls_list = page_url_list(soup, page=20)
dit = get_all_data(urls_list)
save_csv(dit)
爬取完之后,我们用pandas进行读取。
data = pd.read_csv("abstract_data.csv")
data.head()
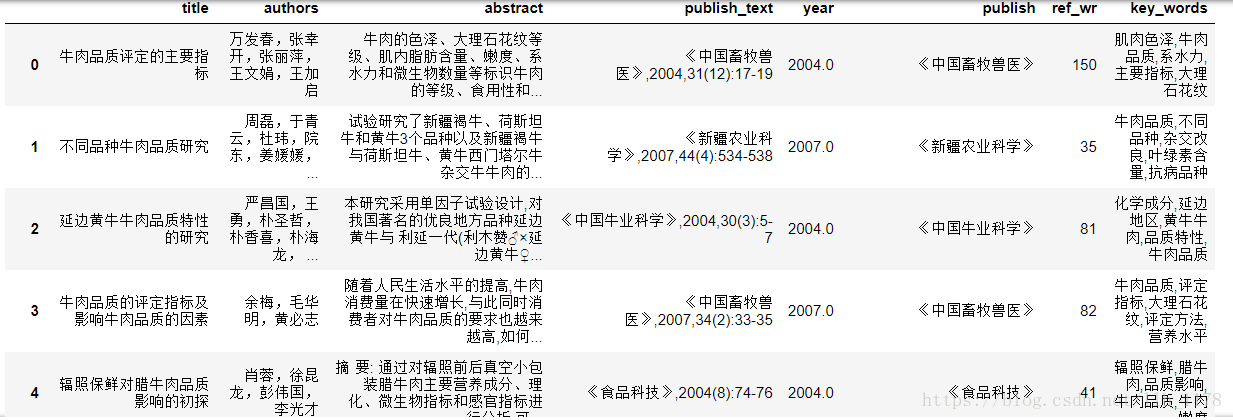
2. 数据清洗及分析
在publish这一列中,还有小问题需要处理。如下,有些行中出现了逗号。
我们将它处理掉。

data["publish"] = data["publish"].map(lambda x: str(x).replace(',', ""))
同时,发现在出版社这一栏南京农业大学有两种表示(《南京农业大学》,南京农业大学),其实它们都是一个意思,需要统一下。
data.publish = data.publish.map(lambda x: re.sub("(.+大学$)", r"《\1》", x))
这样就将所有以“大学”结尾的出版社加上了“《》”进行统一。
data.nunique()
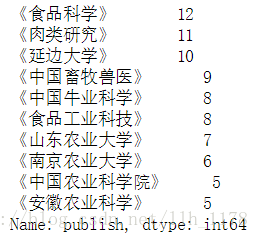
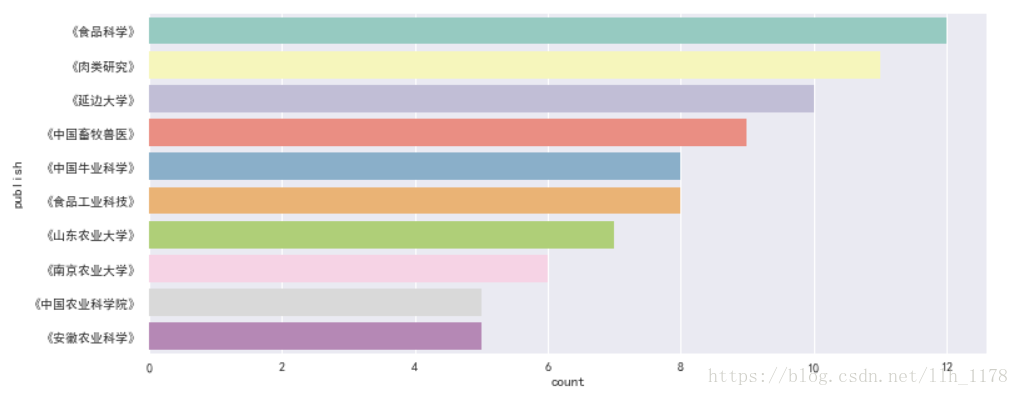
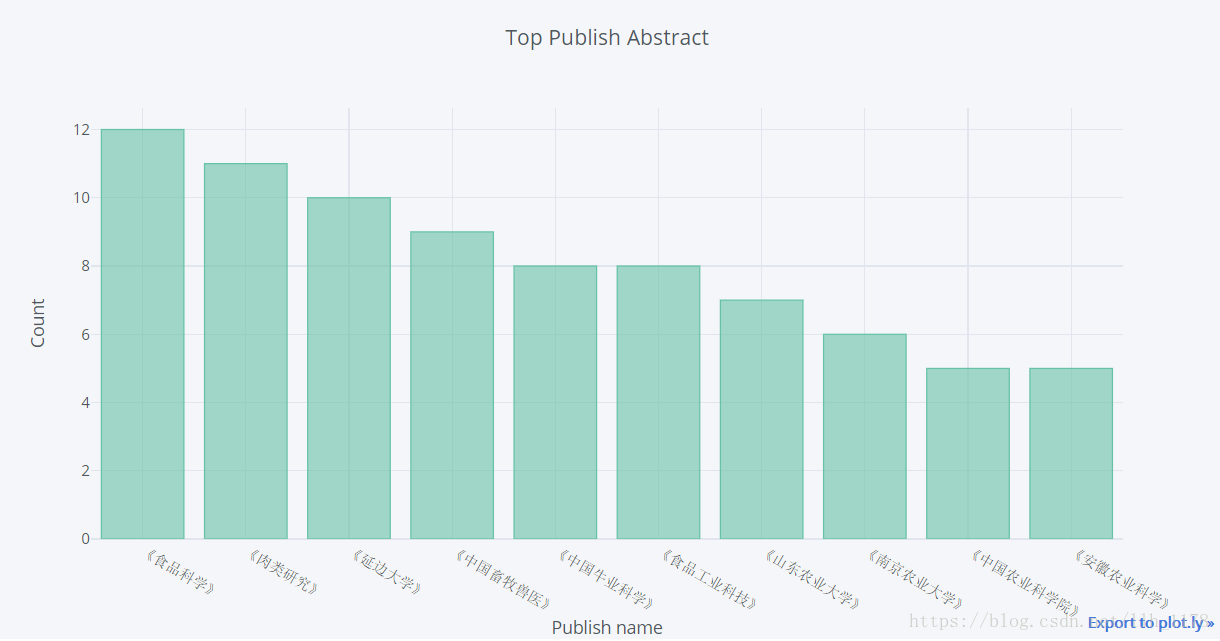
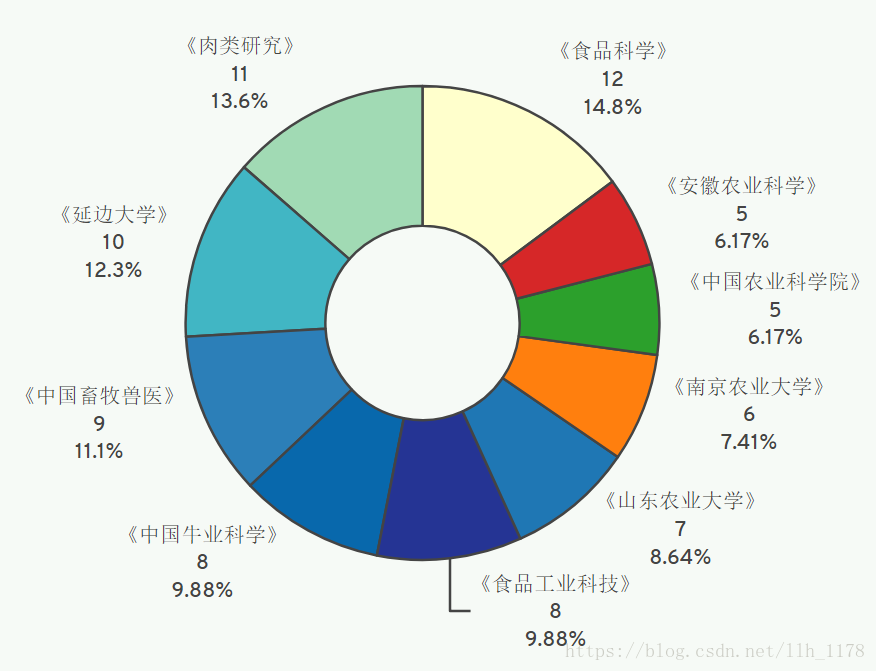
可以看出现在200篇论文中只在91个出版社发表过,我们来统计前10个发表最多的出版社的发表情况。
data.publish.value_counts()[:10]
可视化结果:
首先使用seaborn画图
其次使用Web可视化工具plotly展示
对于“牛肉品质”相关的文章,大家都倾向于投《食品科学》、《肉类研究》、《延边大学》等期刊。
下面,我们接着看这几年来文章发表的情况。
首先,我们先查看数据,有没有缺失值。
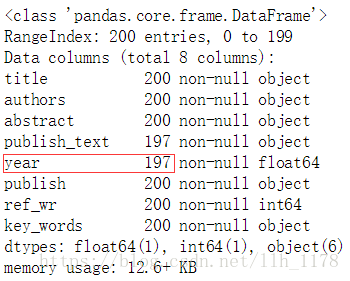
data.info()
这里红框的地方,时间这一列只有197个数据,说明有三个缺失值。因为,缺失值很少,所以,我们直接删除他们。
df = data.dropna(axis=0, how="any")
df.info()
这里,因为“year”列是浮点型的类型,需要转化一下类型。

df["year"] = df["year"].map(lambda x: str(int(x)))
df["year"].value_counts()
进行可视化展示:
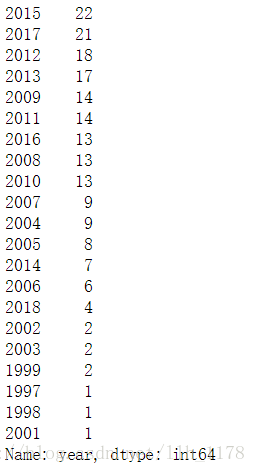
plt.figure(figsize=(12, 5))
# sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']})
temp = df["year"].value_counts()
sns.countplot(
x = df.year,
palette = "Set3",
order = temp.index
)
通过这张图虽然可以看出哪些年发表文章最多,但是却不能展示随时间走势,看到发表趋势。下面就通过时间序列分析的方式展现一下。
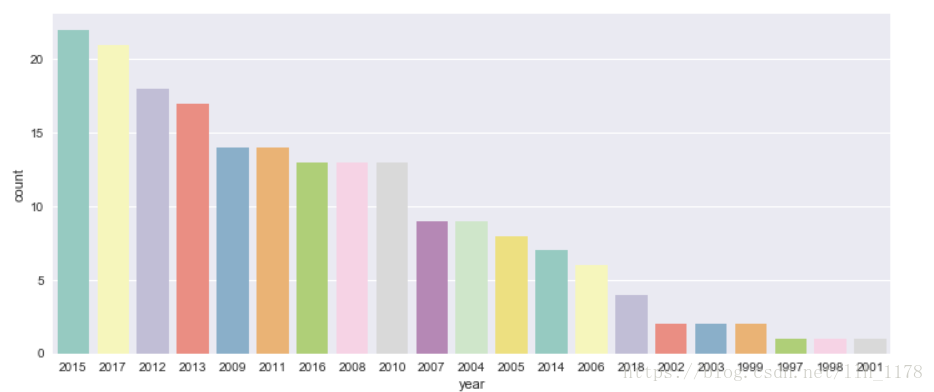
df["year"] = pd.to_datetime(df["year"])
df["year"].value_counts().resample("Y").sum().plot.line()
这样就展示了随时间变化,发表牛肉品质的文章的趋势。但是,还是不够美观。下面使用Web可视化工具plotly再次展示。
这张图就更能展现1997到2018年期间肉牛品质文章的发表情况了,图下方还有一个时间bar,它可以前后拖动,进行放大。这就是使用Web可视化工具的最大好处,可以更加形象具体的可视化展示。
接下来,我们再看哪些作者在1997到2018年期间发表文章最多。
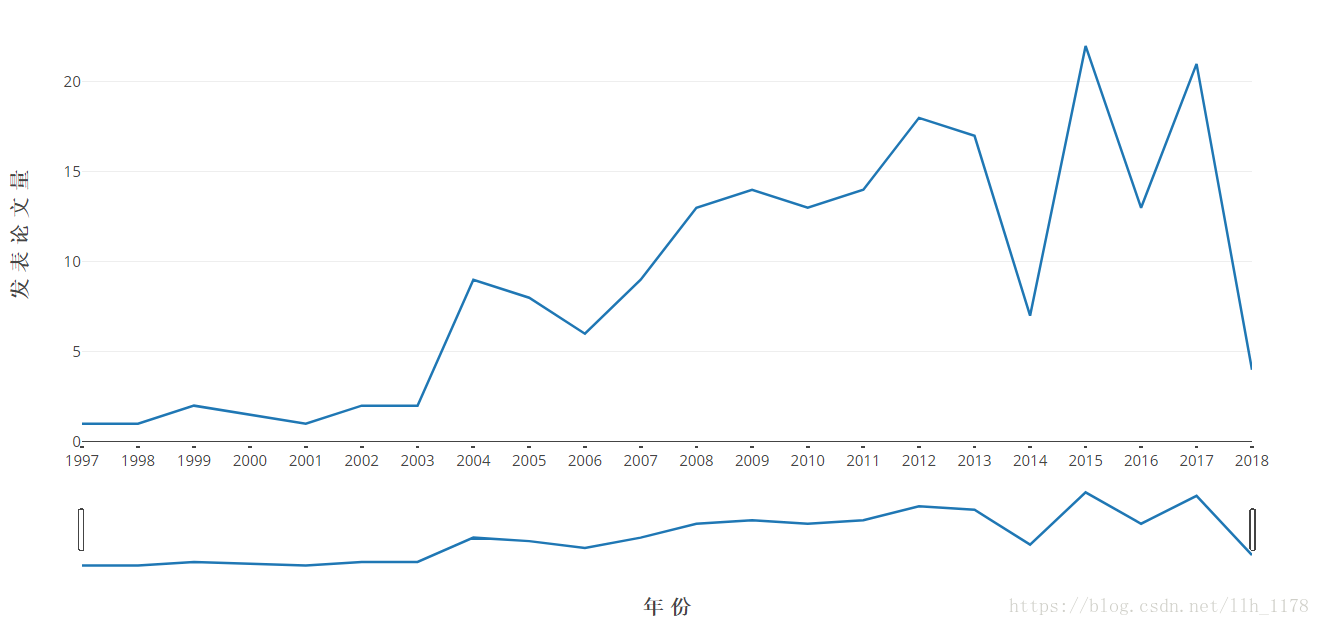
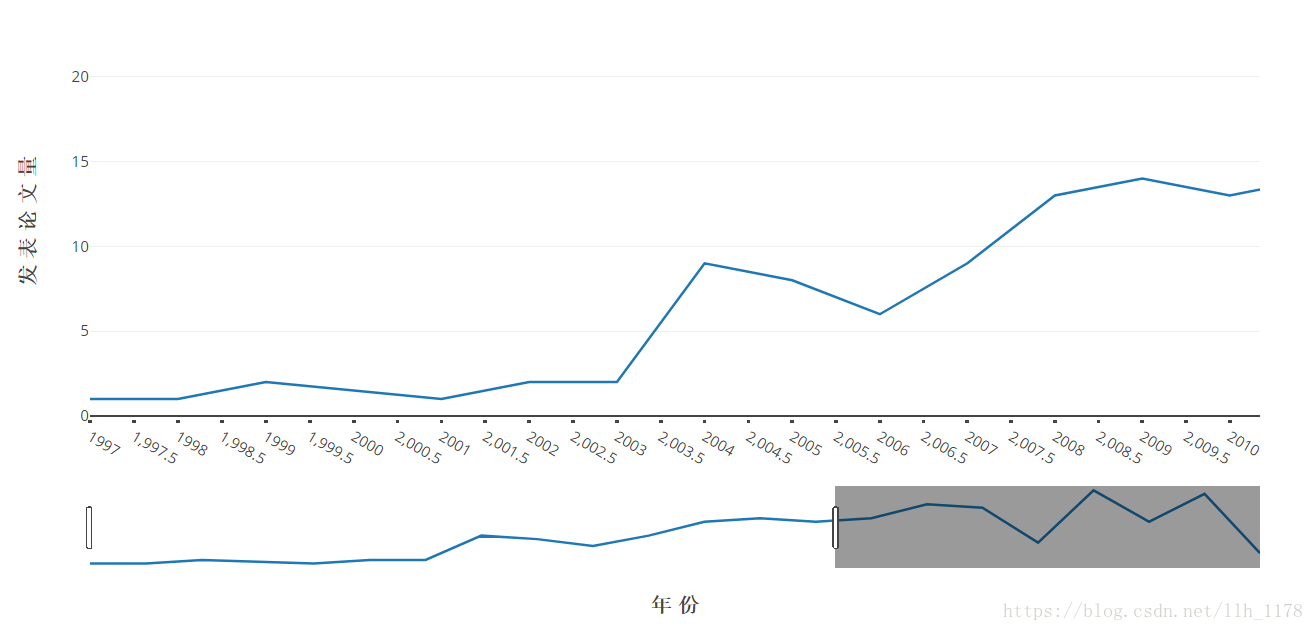
data.authors.value_counts()[:10]
考虑到发表文章的作者数量不统一,因此,我们只提取第一作者进行分析。

data["authors_fir"] = data.authors.map(lambda x: x.split(",")[0])
len(data["authors_fir"].unique())
得出一共有171位不同的作者以第一作者的身份发表过关于“牛肉品质”的文章。
data.authors_fir.value_counts()[:10]
我们再来看发表最多5篇的万发春老师具体是哪五篇文章。

wfc = data[data["authors_fir"] == "万发春"]["title"]
wfc = pd.DataFrame(np.array(wfc), columns=["Title"], index=[1,2,3,4,5])
wfc

3. 词云展示
在这里,我们直接使用关键词进行云词展示,因为,摘要不够完整,且这样也避免了分词处理。
docs = list(data["key_words"].map(lambda x: x.split(",")))
from juba import Similar
S = Similar(docs)
# 词汇表
S.vocabularyList
# 前100个词汇量
tags = S.vocabulary
sort_tage = sorted(tags.items(), key=lambda x: x[1], reverse=True)
sort_tage[:100]
# 打印出词汇和该词汇的出现次数
for v, n in sort_tage[:100]:
print (v + '\t' + str(int(n)))
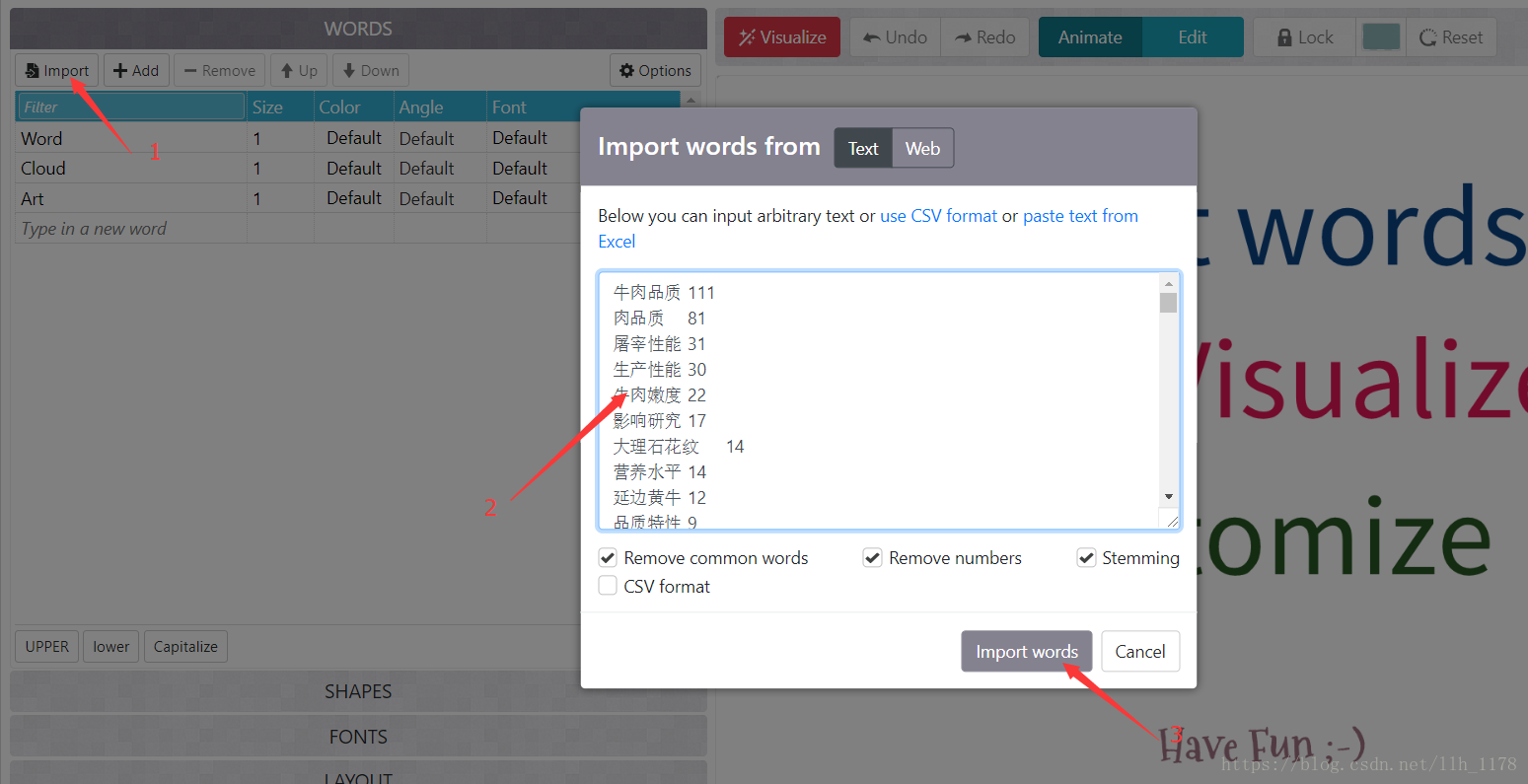
然后,将结果导入https://wordart.com/edit/gvh0mvzkyzem中,如下图:
然后,设置字体和背景图片,注意一点是:中文需要自己加载字体,我使用的微软雅黑字体(网上可以下载)。
最后形成的词云:
到此,第三部分完成,下面我们进行文章相似度分析。

4. 文章相似度分析
考虑到本次爬取的并没有完整的文章且摘要不全的情况,所以只是采用关键词进行分析,因此可能不准,主要介绍方法。但是,后面我将选择一个文本数据集再进行完整的文本相似度分析。
(1)使用juba进行分析。
juba最长使用余弦相似度cosine_sim(self, dtm=none)函数计算文档相似度,都是用于计算第一个文档与其他的文档之间的相似度,其中有dtm有三种参数选择,分别为:“tfidf_dtm”(词频逆文档频率模式)、“prob_dtm”(概率模式)、“tf_dtm”(词频模式)。
sim = S.cosine_sim(dtm="prob_dtm")
sim.insert(0, 1)
data["similar"] = sim
data
然后,我从高到低排列
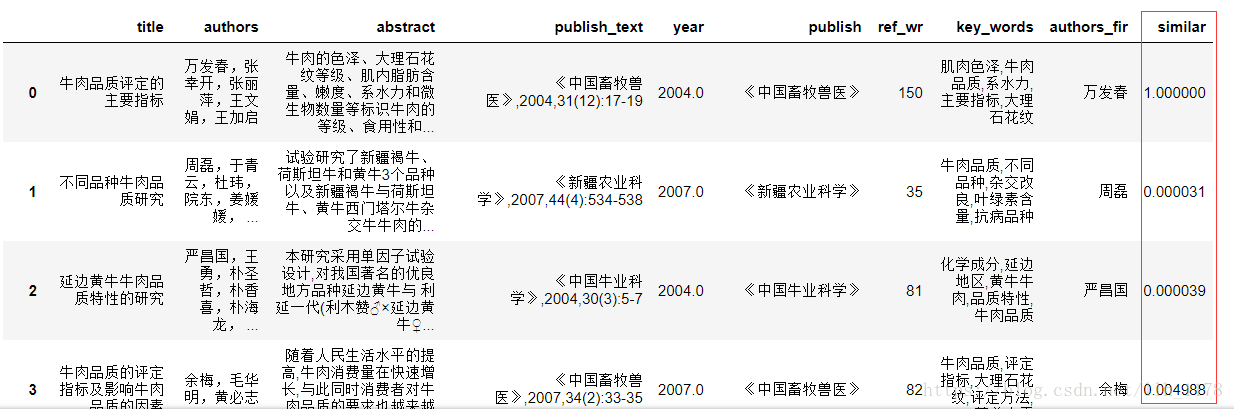
data.sort_values(by="similar", ascending=False)
可以看出文章相似度都很低,这也符合文章发表的规律。
(2)使用graphlab计算相似度
这里,我使用另外一个数据集,它是爬取维基百科上很多名人的介绍的一个文本数据集。
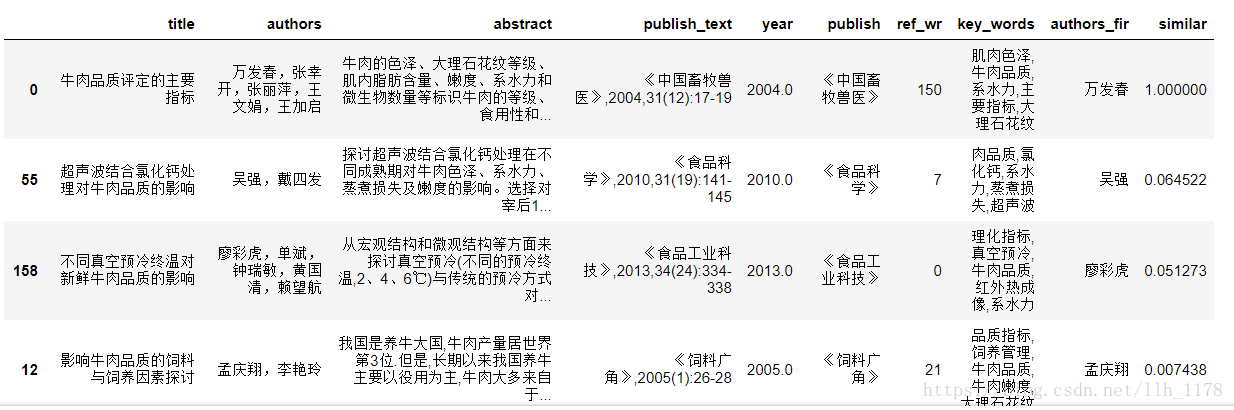
import graphlab
people = graphlab.SFrame.read_csv("people_wiki.csv")
# 去掉索引列
del people["X1"]
people.head()
我们来看一共有多少位名人
len(people.unique())
59071位
我们从中挑选一位名人——奥巴马来看看。
obama = people[people["name"] == "Barack Obama"]
obama

# 查看奥巴马的具体介绍内容
obama["text"]
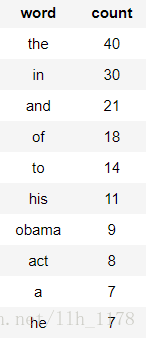
接下来进行词频统计。
obama["word_count"] = graphlab.text_analytics.count_words(obama["text"])
obama_word_count_table = obama[["word_count"]].stack("word_count", new_column_name=["word", "count"])
obama_word_count_table.sort("count", ascending=False)
很显然,“the”、“in”、“and”等停用词的频率最大,但是,这并不是我们想要关注的单词或者说并不是整篇文章的主旨。所以,要使用tfidf进行统计词频。
people["word_count"] = graphlab.text_analytics.count_words(people["text"])
tfidf = graphlab.text_analytics.tf_idf(people["word_count"])
people["tfidf"] = tfidf
people.head()
然后,我们再来看奥巴马的介绍词频。
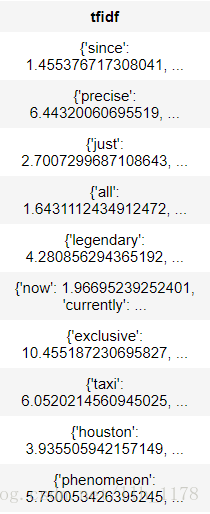
obama[["tfidf"]].stack("tfidf", new_column_name = ["word", "tfidf"]).sort("tfidf", ascending=False)
这样就正常了,直接通过词频就可以看出介绍谁的。
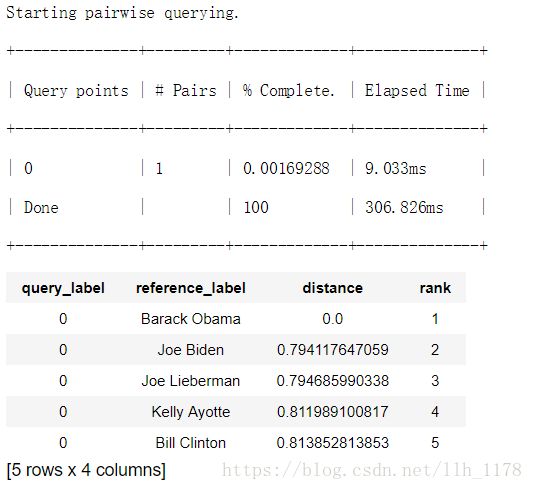
构建knn模型,计算相似度距离。
knn_model = graphlab.nearest_neighbors.create(people, features=["tfidf"], label= 'name')
然后查看与奥巴马相近的名人。
knn_model.query(obama)
这些人大多都是美国的总统或相近的人正是与奥巴马相近,所以,也证实了模型的准确性。至此,整个分析结束,但是也还会存在不少问题,再接再厉吧!














 1657
1657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









