

奇技指南
大家都比较了解哈希表,以及类似php、redis等的内部hash实现。但是本文着力介绍redis中的rehash的实现,供大家参考学习。
本文首发于HULK一线技术杂谈,已授权转载。
引言
redis的性能优越,应用普遍,可以存储键值个数大到可以存储上亿条记录依然保持较高的效率。作为一个内存数据库,redis内部采用了字典的数据结构实现了键值对的存储,字典也就是我们平时所说的哈希表。随着数据量的不断增加,数据必然会产生hash碰撞,而redis采用链地址法解决hash冲突。我们知道如果哈希表数据量达到了一个很大的量级,那么冲突的链的元素数量就会很大,这时查询效率就会变慢,因为取值的时候redis会遍历链表。而随着数据量的缩减,也会产生一定的内存浪费。redis在设计时充分考虑了字典的增加和缩减,为了优化数据量增加时的查询效率和缩减时的内存利用率,redis进行了一系列操作,而处理的这个过程被称作rehash。
两个hashtable
我们先来看一下字典在redis源码中的定义
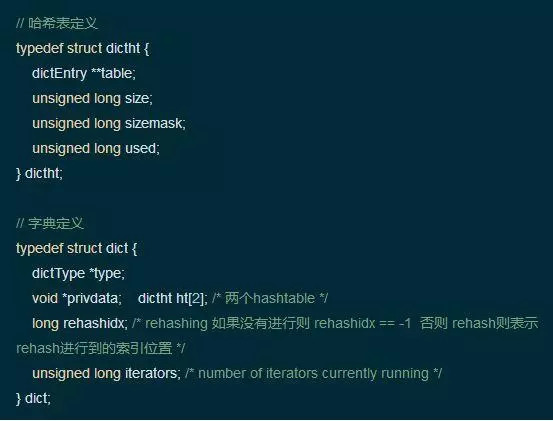
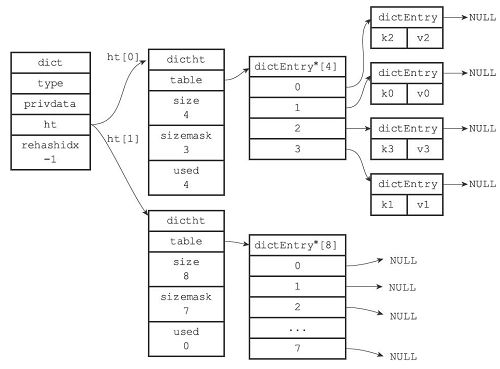
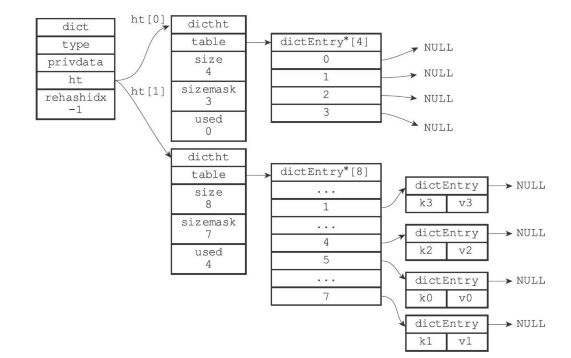
从结构上看每个字典中都包含了两个hashtable。那么为什么一个字典会需要两个hashtable?首先redis在正常读写时会用到一个hashtable,而另一个hashtable的作用实际上是作为字典在进行rehash时的一个临时载体。我们可以这么理解,redis开始只会用一个hashtable去读写,如果这个hashtable的数据量增加或者缩减到某个值,到达了rehash的条件,redis便会开始根据数据量和链(bucket)的个数初始化那个备用的hashtable,来使这个hashtable从容量上满足后续的使用,并开始把之前的hashtable的数据迁移到这个新的hashtable上来,当然这种迁移是对每个节点值进行一次hash运算。等到数据全部迁移完成,再进行一次hashtable的地址更名,把这个备用的hashtable为正式的hashtable,同时清空另一个hashtable以供下一次rehash使用。
rehash的条件
hashtable元素总个数 / 字典的链个数 = 每个链平均存储的元素个数(load_factor)
-
服务器目前没有在执行BGSAVE命令或者BGREWRITEAOF命令,load_factor >= 1,dict就会触发扩大操作rehash
-
服务器目前正在执行BGSAVE命令或者BGREWRITEAOF命令,load_factor >= 5,dict就会触发扩大操作rehash
-
load_factor < 0.1,dict就会触发缩减操作rehash
2
rehash的过程
我们假设 ht[0]为正在使用的hashtable,ht[1]为rehash之后的备用hashtable
步骤如下:
-
为字典的备用哈希表分配空间:
-
如果执行的是扩展操作,那么备用哈希表的大小为第一个大于等于(已用节点个数)*2的2n(2的n次方幂)
-
如果执行的是收缩操作,那么备用哈希表的大小为第一个大于等于(已用节点个数)的2n
-
在字典中维持一个索引计数器变量rehashidx,并将它的值设置为0,表示rehash工作正式开始(为-1时表示没有进行rehash)。
-
rehash进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当一次rehash工作完成之后,程序将rehashidx属性的值+1。同时在serverCron中调用rehash相关函数,在1ms的时间内,进行rehash处理,每次仅处理少量的转移任务(100个元素)。
-
随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被rehash至ht[1],这时程序将rehashidx属性的值设为-1,表示rehash操作已完成。
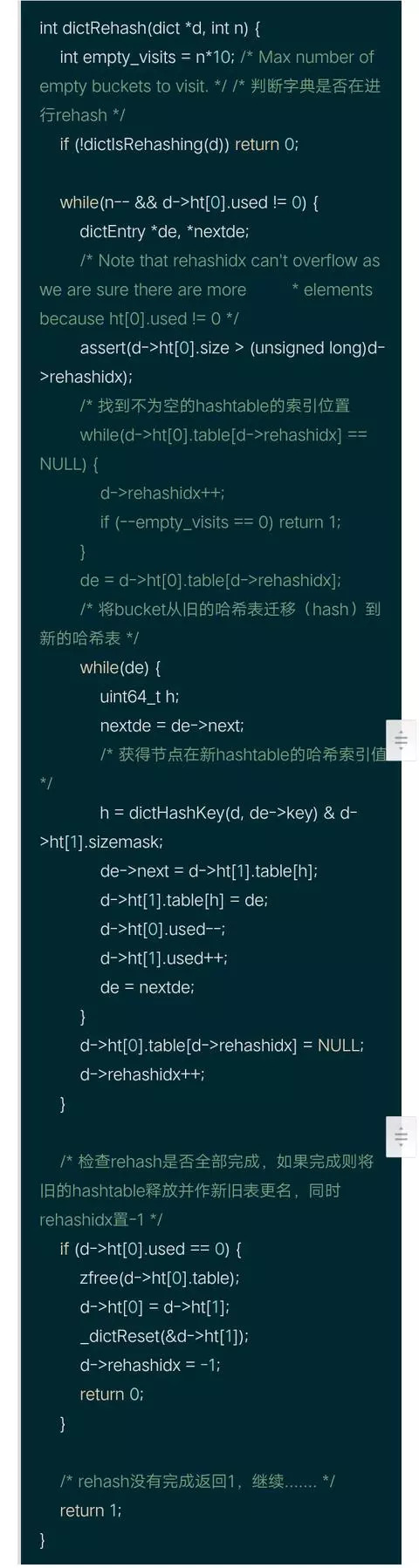
rehash部分源码:
举个例子
-
rehash开始,初始化ht[1]
-
对k2进行rehash
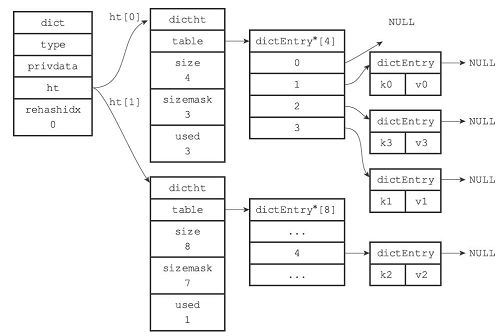
-
rehash完成
总结
这种渐进式的 rehash 避免了集中式rehash带来的庞大计算量和内存操作,但是需要注意的是redis在进行rehash的时候,正常的访问请求可能需要做多要访问两次hashtable(ht[0], ht[1]),例如键值被rehash到新ht[1],则需要先访问ht[0],如果ht[0]中找不到,则去ht[1]中找。
界世的你当不
只作你的肩膀
无


360官方技术公众号
技术干货|一手资讯|精彩活动
空·
